I am trying to do exactly what the title says. What I have is the log-likelihood function as follows:
Likelihood function, where $I_i = 1$ when $X_i = 0$, and $I_i = 0$ otherwise. Then I took the partial derivatives of that like this. I tried simplifying this expression to get an equation, but I keep getting nonsense. After searching the web, I found this book but I don't understand how the author arrived at ML equations just from looking at the PGF, can someone help explain that please? There is also this entry but they use a different model from mine (p = probability of Poisson, 1-p = probability of 0, whereas both the first book and my model use p = probability of 0, 1-p = probability of Poisson) and again they don't show the simplification steps so I can't really use that. Thanks for any help.

{kind=link}
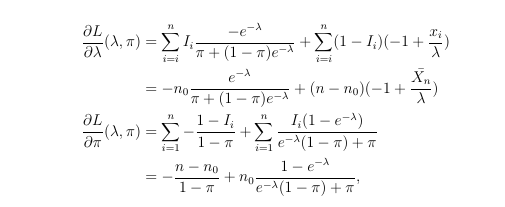{kind=link}
{kind=link}
{kind=link}
The book you have referenced uses some general theory about zero-inflated distributions (i.e., the application of some results that are not specific to the Poisson case). I have been unable to replicate its results, and indeed, it appears to me that its equation (8.20) is incorrect (and the distribution is not a power series distribution once you substitute the MLE for the zero-inflation parameter). My own calculations for the MLE are given below, applying standard optimisation methods. My results agree with your book for the estimation of the zero-inflation parameter, but diverge in the estimate of the rate parameter in the Poisson distribution.
The zero-inflated Poisson probability mass function (with zero-inflation parameter $0 \leqslant \pi \leqslant 1$) is:
$$\begin{equation} \begin{aligned} p(x | \pi, \lambda) &= \pi \mathbb{I}(x=0) + (1-\pi) \cdot \text{Pois}(x|\lambda) \\[8pt] &= \begin{cases} \pi + (1-\pi) \cdot \exp(- \lambda) & & & \text{for } x = 0, \\[6pt] (1-\pi) \cdot \frac{\lambda^x}{x!} \exp(- \lambda) & & & \text{for } x > 0. \end{cases} \end{aligned} \end{equation}$$
MLE of zero-inflated Poisson data: Suppose we have a sample of $n$ IID data values from this distribution. To facilitate our analysis we let $r_0 \equiv \frac{1}{n} \sum_{i=1}^n \mathbb{I}(x_i=0)$ be the proportion of observed zeros in this data and we let $\bar{x} \equiv \tfrac{1}{n} \sum_{i=1}^n x_i$ be the sample mean. The corresponding log-likelihood for this data can then be written as:
$$\ell_\mathbf{x}(\pi, \lambda) = n r_0 \ln (\pi + (1-\pi) \cdot \exp(- \lambda)) + n (1-r_0) ( \ln(1-\pi) - \lambda ) + n \bar{x} \ln \lambda .$$
We therefore have:
$$\frac{\partial \ell_\mathbf{x}}{\partial \pi}(\pi, \lambda) = n \Bigg[ r_0 \cdot \frac{1-\exp(-\lambda)}{\pi + (1-\pi) \exp(-\lambda)} - \frac{1-r_0}{1-\pi} \Bigg].$$
We refer to the condition that $r_0 \geqslant \exp (-\bar{x})$ as the zero-inflated condition (i.e., there is an empirical excess of zeros relative to the regular Poisson model). We have the partial-MLE:
$$\hat{\pi}(\lambda) = \begin{cases} \frac{r_0 - \exp(-\lambda)}{1-\exp(-\lambda)} & & & \text{Under the zero-inflated condition}, \\[6pt] \text{ } 0 & & & \text{otherwise}. \end{cases}$$
Under the zero-inflated condition it can easily be shown that $\hat{\pi}(\lambda) + (1-\hat{\pi}(\lambda)) \cdot \exp(- \lambda) = r_0$ and $1-\hat{\pi}(\lambda) = (1-r_0)/(1-\exp(-\lambda))$, so that substituting back into the log-likelihood function (under the zero-inflated condition) gives us the partially-maximised function (called the profile log-likelihood):
$$\ell_\mathbf{x}^*(\lambda) = \ell_\mathbf{x}(\hat{\pi}(\lambda), \lambda) = - n(1-r_0) [ \lambda + \ln ( 1-\exp(-\lambda) ) ] + n \bar{x} \ln \lambda + \text{const}.$$
We therefore have:
$$\begin{align} \frac{d \ell_\mathbf{x}^*}{d \lambda}(\lambda) &= n \Bigg[ \frac{\bar{x}}{\lambda} - (1-r_0) \Big( 1 + \frac{\lambda e^{-\lambda}}{1-e^{-\lambda}} \Big) \Bigg] , \\[6pt] \frac{d^2 \ell_\mathbf{x}^*}{d \lambda^2}(\lambda) &= - n \Bigg[ \frac{\bar{x}}{\lambda^2} + (1-r_0) \cdot \frac{(1-\lambda^2 - e^{-\lambda}) e^{-\lambda}}{(1-e^{-\lambda})^2} \Bigg]. \\[6pt] \end{align}$$
The corresponding MLE $\hat{\lambda}$ does not have a closed form solution, so it must be obtained numerically by solving the critical-point-equation:
$$\bar{x}(1-e^{-\hat{\lambda}}) = \hat{\lambda} (1-r_0) ( 1-e^{-\hat{\lambda}}+\lambda e^{-\hat{\lambda}} ).$$
Note that this is different to equation (8.20) in the book you cite. I have been unable to replicate the result in the book.